xen-create-image, которая в значительной мере автоматизирует задачу. Единственный обязательный параметр — --hostname, передающий имя domU; другие опции важны, но они могут быть сохранены в конфигурационном файле /etc/xen-tools/xen-tools.conf, и их отсутствие в командной строке не вызовет ошибки. Поэтому следует проверить содержимое этого файла перед созданием образов, или же использовать дополнительные параметры в вызове xen-create-image. Отметим следующие важные параметры:
--memory для указания количества ОЗУ, выделенного вновь создаваемой системе;
--size и --swap, чтобы задать размер «виртуальных дисков», доступных для domU;
--debootstrap-cmd, to specify the which debootstrap command is used. The default is debootstrap if debootstrap and cdebootstrap are installed. In that case, the --dist option will also most often be used (with a distribution name such as bullseye).
--dhcp объявляет, что конфигурация сети domU должна быть получена по DHCP, в то время как --ip позволяет задать статический IP-адрес.
--dir, заключается в создании одного файла на dom0 для каждого устройства, которое будет передано domU. Для систем, использующих LVM, альтернативой является использование опции --lvm, за которой указывается имя группы томов; в таком случае xen-create-image создаст новый логический том в этой группе, и этот логический том станет доступным для domU как жёсткий диск.
#xen-create-image --hostname testxen --dhcp --dir /srv/testxen --size=2G --dist=bullseye --role=udevGeneral Information -------------------- Hostname : testxen Distribution : bullseye Mirror : http://deb.debian.org/debian Partitions : swap 512M (swap) / 2G (ext4) Image type : sparse Memory size : 256M Bootloader : pygrub [...] Logfile produced at: /var/log/xen-tools/testxen.log Installation Summary --------------------- Hostname : testxen Distribution : bullseye MAC Address : 00:16:3E:C2:07:EE IP Address(es) : dynamic SSH Fingerprint : SHA256:K+0QjpGzZOacLZ3jX4gBwp0mCESt5ceN5HCJZSKWS1A (DSA) SSH Fingerprint : SHA256:9PnovvGRuTw6dUcEVzzPKTITO0+3Ki1Gs7wu4ke+4co (ECDSA) SSH Fingerprint : SHA256:X5z84raKBajUkWBQA6MVuanV1OcV2YIeD0NoCLLo90k (ED25519) SSH Fingerprint : SHA256:VXu6l4tsrCoRsXOqAwvgt57sMRj2qArEbOzHeydvV34 (RSA) Root Password : FS7CUxsY3xkusv7EkbT9yae
vif*, veth*, peth* и xenbr0. Гипервизор Xen комбинирует их в соответствии с заданной схемой под контролем инструментов пространства пользователя. Поскольку NAT и маршрутизируемая модель приспособлены лишь для отдельных случаев, мы рассмотрим только модель моста.
xend daemon is configured to integrate virtual network interfaces into any pre-existing network bridge (with xenbr0 taking precedence if several such bridges exist). We must therefore set up a bridge in /etc/network/interfaces (which requires installing the bridge-utils package, which is why the xen-utils package recommends it) to replace the existing eth0 entry (be careful to use the correct network device name):
auto xenbr0
iface xenbr0 inet dhcp
bridge_ports eth0
bridge_maxwait 0
xl. Эта команда позволяет производить различные манипуляции с доменами, в частности выводить их список, запускать их и останавливать. Может понадобиться увеличить объём памяти по умолчанию, отредактировав значение переменной memory в конфигурационном файле (в данном случае — /etc/xen/testxen.cfg). Здесь мы установили его в 1024 (мегабайт).
#xl listName ID Mem VCPUs State Time(s) Domain-0 0 3918 2 r----- 35.1 #xl create /etc/xen/testxen.cfgParsing config from /etc/xen/testxen.cfg #xl listName ID Mem VCPUs State Time(s) Domain-0 0 2757 2 r----- 45.2 testxen 3 1024 1 r----- 1.3
testxen использует реальную память, взятую из ОЗУ, которая иначе была бы доступна dom0, а не виртуальную. Поэтому при сборке сервера для размещения машин Xen следует побеспокоиться об обеспечении достаточного объёма физического ОЗУ.
hvc0 с помощью команды xl console:
#xl console testxen[...] Debian GNU/Linux 11 testxen hvc0 testxen login:
xl pause и xl unpause. Заметьте, что хотя приостановленный domU не использует ресурсы процессора, выделенная ему память по-прежнему занята. Может иметь смысл использовать команды xl save и xl restore: сохранение domU освобождает ресурсы, которые ранее использовались этим domU, в том числе и ОЗУ. После восстановления (или снятия с паузы) domU не замечает ничего кроме того, что прошло некоторое время. Если domU был запущен, когда dom0 выключается, сценарии из пакетов автоматически сохраняют domU и восстанавливают его при следующей загрузке. Отсюда, конечно, проистекает обычное неудобство, проявляющееся, например, при переводе ноутбука в спящий режим; в частности, если domU приостановлен слишком надолго, сетевые подключения могут завершиться. Заметьте также, что Xen на данный момент несовместим с большей частью системы управления питанием ACPI, что мешает приостановке dom0-системы.
shutdown), так и из dom0, с помощью xl shutdown или xl reboot.
xl требуют одного или более аргументов, часто — имени domU. Эти аргументы подробно описаны в странице руководства xl(1).
init, и получившийся набор будет выглядеть чрезвычайно похоже на виртуальную машину. Официальное название для такой схемы «контейнер» (отсюда и неофициальное название LXC: LinuX Containers), но весьма значительным отличием от «настоящих» виртуальных машин, таких как предоставляемые Xen или KVM, заключается в отсутствии второго ядра; контейнер использует то же самое ядро, что и хост-система. У этого есть как преимущества, так и недостатки: к преимуществам относится великолепная производительность благодаря полному отсутствию накладных расходов, а также тот факт, что ядро видит все процессы в системе, поэтому планировщик может работать более эффективно, чем если бы два независимых ядра занимались планированием выполнения разных наборов задач. Основное из неудобств — невозможность запустить другое ядро в контейнере (как другую версию Linux, так и другую операционную систему).
/sys/fs/cgroup. Так как Debian 8 перешел на systemd, который также зависит от control groups, это делается автоматически во время загрузки без дополнительной настройки.
/etc/network/interfaces, moving the configuration for the physical interface (for instance, eth0 or enp1s0) to a bridge interface (usually br0), and configuring the link between them. For instance, if the network interface configuration file initially contains entries such as the following:
auto eth0 iface eth0 inet dhcp
auto br0
iface br0 inet dhcp
bridge-ports eth0eth0, и интерфейсы, заданные для контейнеров.
/etc/network/interfaces тогда примет следующий вид:
# Interface eth0 is unchanged
auto eth0
iface eth0 inet dhcp
# Virtual interface
auto tap0
iface tap0 inet manual
vde2-switch -t tap0
# Bridge for containers
auto br0
iface br0 inet static
bridge-ports tap0
address 10.0.0.1
netmask 255.255.255.0
br0.
#lxc-create -n testlxc -t debiandebootstrap is /usr/sbin/debootstrap Checking cache download in /var/cache/lxc/debian/rootfs-stable-amd64 ... Downloading debian minimal ... I: Retrieving Release I: Retrieving Release.gpg [...] Download complete. Copying rootfs to /var/lib/lxc/testlxc/rootfs... [...] #
/var/cache/lxc, а затем перемещена в каталог назначения. Это позволяет создавать идентичные контейнеры намного быстрее, поскольку требуется лишь скопировать их.
--arch с указанием архитектуры системы для установки и опцию --release, если вы хотите установить что-то отличное от текущего стабильного релиза Debian. Вы можете также установить переменную окружения MIRROR, чтобы указать на локальное зеркало Debian.
lxcbr0, which by default is used by all newly created containers via /etc/lxc/default.conf and the lxc-net service:
lxc.net.0.type = veth lxc.net.0.link = lxcbr0 lxc.net.0.flags = up
lxcbr0 bridge on the host. You will find these settings in the created container's configuration (/var/lib/lxc/testlxc/config), where also the device' MAC address will be specified in lxc.net.0.hwaddr. Should this last entry be missing or disabled, a random MAC address will be generated.
lxc.uts.name = testlxc
lxc-start --name=testlxc.
lxc-attach -n testlxc passwd if we want. We can login with:
#lxc-console -n testlxcConnected to tty 1 Type <Ctrl+a q> to exit the console, <Ctrl+a Ctrl+a> to enter Ctrl+a itself Debian GNU/Linux 11 testlxc tty1 testlxc login:rootPassword: Linux testlxc 5.10.0-11-amd64 #1 SMP Debian 5.10.92-1 (2022-01-18) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. Last login: Wed Mar 9 01:45:21 UTC 2022 on console root@testlxc:~#ps auxwfUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.2 18964 11464 ? Ss 01:36 0:00 /sbin/init root 45 0.0 0.2 31940 10396 ? Ss 01:37 0:00 /lib/systemd/systemd-journald root 71 0.0 0.1 99800 5724 ? Ssl 01:37 0:00 /sbin/dhclient -4 -v -i -pf /run/dhclient.eth0.pid [..] root 97 0.0 0.1 13276 6980 ? Ss 01:37 0:00 sshd: /usr/sbin/sshd -D [listener] 0 of 10-100 startups root 160 0.0 0.0 6276 3928 pts/0 Ss 01:46 0:00 /bin/login -p -- root 169 0.0 0.0 7100 3824 pts/0 S 01:51 0:00 \_ -bash root 172 0.0 0.0 9672 3348 pts/0 R+ 01:51 0:00 \_ ps auxwf root 164 0.0 0.0 5416 2128 pts/1 Ss+ 01:49 0:00 /sbin/agetty -o -p -- \u --noclear [...] root@testlxc:~#
/var/lib/lxc/testlxc/rootfs). Мы можем выйти из консоли с помощью Control+a q.
lxc-start starting using the --daemon option by default. We can interrupt the container with a command such as lxc-stop --name=testlxc.
lxc-autostart, запускающую контейнеры, параметр lxc.start.auto которых установлен в значение 1). Более тонкий контроль порядка запуска возможен с помощью lxc.start.order и lxc.group: по умолчанию сценарий инициализации сначала запускает контейнеры, входящие в группу onboot, а затем — контейнеры, не входящие ни в какие группы. В обоих случаях порядок внутри группы определяется параметром lxc.start.order.
qemu-*: речь всё равно о KVM.
/proc/cpuinfo.
virt-manager is a graphical interface that uses libvirt to create and manage virtual machines.
apt-get install libvirt-clients libvirt-daemon-system qemu-kvm virtinst virt-manager virt-viewer. libvirt-bin предоставляет демон libvirtd, позволяющий (возможно удалённо) управлять виртуальными машинами, запущенными на хосте, и запускает необходимые виртуальные машины при загрузке хоста. libvirt-clients предоставляет утилиту virsh с интерфейсом командной строки, которая позволяет контролировать виртуальные машины, управляемые libvirt.
virt-install, которая позволяет создавать виртуальные машины из командной строки. Наконец, virt-viewer позволяет получать доступ к графической консоли виртуальной машины.
eth0 и мост br0, и что первый присоединён к последнему.
libvirtd where to store the disk images, unless the default location (/var/lib/libvirt/images/) is fine.
#mkdir /srv/kvm#virsh pool-create-as srv-kvm dir --target /srv/kvmPool srv-kvm created #
virt-install. Эта команда регистрирует виртуальную машину и её параметры в libvirtd, а затем запускает её, чтобы приступить к установке.
#virt-install --connect qemu:///system--virt-type kvm
--name testkvm
--memory 2048
--disk /srv/kvm/testkvm.qcow,format=qcow2,size=10
--cdrom /srv/isos/debian-11.2.0-amd64-netinst.iso
--network bridge=virbr0
--graphics vnc
--os-type linux
--os-variant debiantesting
Starting install... Allocating 'testkvm.qcow'
|
Опция --connect указывает, какой «гипервизор» использовать. Он указывается в виде URL, содержащего систему виртуализации(xen://, qemu://, lxc://, openvz://, vbox:// и т. п.) и машину, на которой должны размещаться виртуальные машины (это поле можно оставить пустым в случае локального узла). В дополнение к этому, в случае QEMU/KVM каждый пользователь может управлять виртуальными машинами, работающими с ограниченными правами, и путь URL позволяет дифференцировать «системные» машины (/system) от остальных (/session).
|
|
Так как KVM управляется тем же образом, что и QEMU, в --virt-type kvm можно указать использование KVM, хотя URL и выглядит так же, как для QEMU.
|
|
Опция --name задаёт (уникальное) имя виртуальной машины.
|
|
Опция --memory позволяет указать объём ОЗУ (в МБ), который будет выделен виртуальной машине.
|
| --disk служит для указания местоположения файла образа, который будет представляться жёстким диском виртуальной машины; этот файл создаётся, если только ещё не существует, а его размер (в ГБ) указывается параметром size. Параметр format позволяет выбрать из нескольких способов хранения образа файла. Формат по умолчанию (qcow2) позволяет начать с небольшого файла, увеличивающегося только по мере того, как виртуальная машина использует пространство.
|
|
Опция --cdrom используется, чтобы указать, где искать оптический диск для установки. Путь может быть либо локальным путём к ISO-файлу, либо URL, по которому можно получить файл, либо файлом устройства физического привода CD-ROM (то есть /dev/cdrom).
|
|
С помощью опции --network указывается, каким образом виртуальная сетевая карта интегрируется в сетевую конфигурацию хоста. Поведением по умолчанию (которое мы задали явно в этом примере) является интеграция в любой существующий сетевой мост. Если ни одного моста нет, виртуальная машина сможет получить доступ к физической сети только через NAT, поэтому она получает адрес в подсети из частного диапазона (192.168.122.0/24).
The default network configuration, which contains the definition for a virbr0 bridge interface, can be edited using virsh net-edit default and started via virsh net-start default if not already done automatically during system start.
|
| --graphics vnc означает, что подключение к графической консоли нужно сделать доступным через VNC. По умолчанию соответствующий VNC-сервер слушает только на локальном интерфейсе; если VNC-клиент должен запускаться на другой системе, для подключения потребуется использовать SSH-туннель (см. Раздел 9.2.1.4, «Создание шифрованных туннелей»). Как вариант, можно использовать опцию --graphics vnc,listen=0.0.0.0, чтобы VNC-сервер стал доступен на всех интерфейсах; заметьте, что если вы сделаете так, вам серьёзно стоит заняться настройкой межсетевого экрана.
|
|
Опции --os-type и --os-variant позволяют оптимизировать некоторые параметры виртуальной машины, исходя из известных особенностей указанной операционной системы.
The full list of OS types can be shown using the osinfo-query os command from the libosinfo-bin package.
|
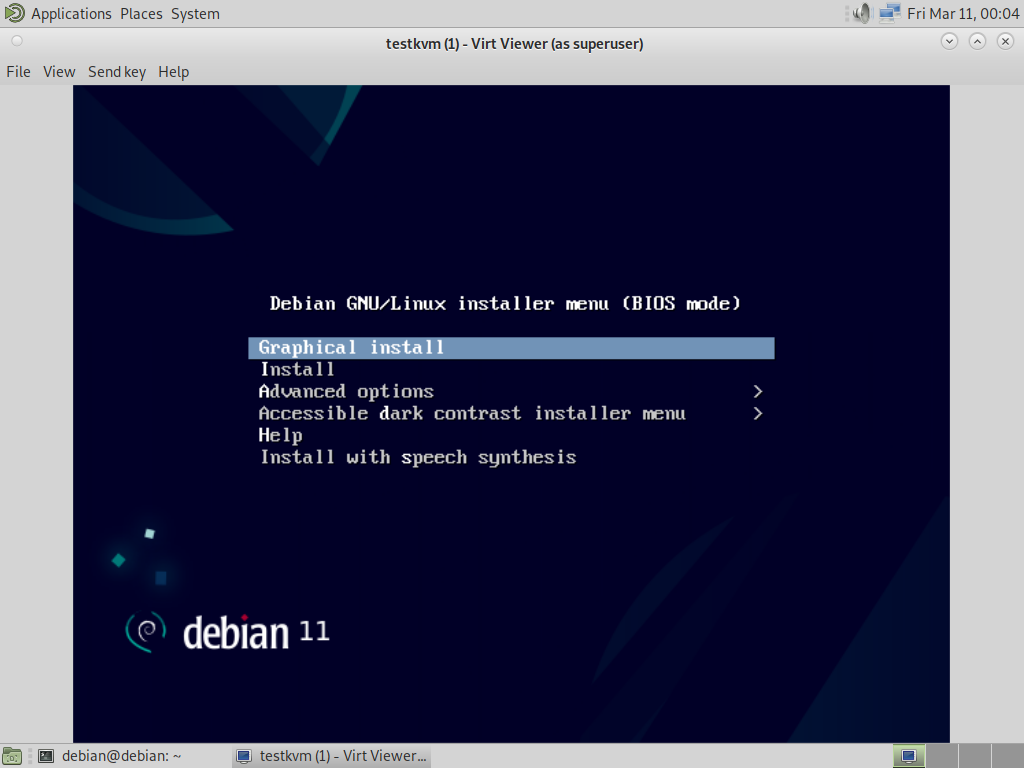
virt-viewer в любом графическом окружении (пароль root на удалённой машине запрашивается дважды, поскольку для работы требуется два SSH-соединения):
$virt-viewer --connect qemu+ssh://root@server/system testkvmroot@server's password: root@server's password:
libvirtd список управляемых им виртуальных машин:
#virsh -c qemu:///system list --all Id Name State ---------------------------------- 8 testkvm shut off
#virsh -c qemu:///system start testkvmDomain testkvm стартует
vncviewer):
#virsh -c qemu:///system vncdisplay testkvm127.0.0.1:0
virsh входят:
reboot для перезапуска виртуальной машины;
shutdown для корректного завершения работы;
destroy для грубого прерывания работы;
suspend для временной приостановки;
resume для продолжения работы после приостановки;
autostart для включения (или для выключения, с опцией --disable) автоматического запуска виртуальной машины при запуске хост-системы;
undefine для удаления всех следов виртуальной машины из libvirtd.